参加者レポート - GPUクラウドAI推進プログラム -
生成AIを用いたコードレビューの負担改善について
株式会社プロシーズ

- 中間レポート
- 最終レポート
2024年7月時点
開発/研究の目的
本プロジェクトでは、アプリケーションのソースコードや機能仕様書、そして過去にGitHub上で行われたコードレビュー情報をもとに、AIが自動でコードレビューを行うシステムを開発しています。
大きく3つの課題を解決することを目指しています。
1つ目はコード品質のばらつきをなくすことです。
コードレビューは品質管理に欠かせない工程ですが、人によって評価基準が異なるため一定のばらつきが生まれがちです。
AIによるレビューを導入することで、バグやセキュリティリスクを安定して検出し、コード全体の品質を高められます。
2つ目はレビューにかかる時間を減らすことです。
開発者がコードを書くのと同じくらいの時間をレビューに費やすのは非効率的なため、AIの導入によって時間短縮を狙い、開発者が創造的な業務に集中できるようにします。
3つ目は新人開発者の学習支援です。
過去のコードレビュー情報を学習したAIは、ベストプラクティスを一貫して適用できます。
これにより、レビューを受ける側も効率よく知識やスキルを習得できます。
全体のプロセス
本開発は、以下の5つのステップで進めています。
1.データ収集と前処理
まず、ソースコードや機能仕様書、過去のコードレビュー情報を集め、必要に応じて形式を整理します。
2.GPUサーバーの設定とLlama3のインストール
続いて、GPUサーバーをセットアップし、最新の大規模言語モデルであるLlama3をインストールします。
3.モデルのトレーニング
集めたデータを使ってLlama3を学習させます。コードレビューの内容やベストプラクティスを繰り返し学習させることで、精度を高めていきます。
4.モデルの評価とチューニング
学習後のモデルを評価し、不十分な点や修正が必要な部分を洗い出します。モデルのパラメータを再調整しながら最適化を行います。
5.実運用とフィードバック収集
完成したモデルを実際の開発現場に導入し、AIによるコードレビューを実行します。得られたフィードバックをもとに、さらなる改善を図ります。
使用されているAI技術やアルゴリズム
本プロジェクトでは、自然言語処理(NLP)と機械学習の手法を中心に利用しています。 主にLlama3という最新の大規模言語モデル(LLM)を活用し、Transformerアーキテクチャに基づいて学習させる想定です。
データ前処理の段階では、ソースコードやテキストデータをトークン化し、扱いやすい形式に変換します。 ソースコードにはコード特有の構造があるため、コード専用のトークナイザを使い、機能仕様書や過去のレビュー文面には自然言語処理向けのトークン化技術を適用します。
学習の方法としては、集めたデータを段階的にLlama3に入力しながら、教師付き学習(Supervised Learning)でモデルを訓練します。 評価とチューニングの段階では、クロスバリデーションやグリッドサーチなどを行い、精度(Accuracy)、適合率(Precision)、再現率(Recall)などを指標に性能を高める方針です。
システム構成
●データ収集と前処理
PythonやPandas、NLTKを用いて、ソースコード・仕様書・コードレビュー内容をまとめて形式を統一します。
●モデルのトレーニング
PyTorchとCUDAによるGPUアクセラレーションを活用し、学習処理を高速化しています。評価やチューニングにはScikit-learnを使い、クロスバリデーションやグリッドサーチで最適化を行います。
●データ&モデルのバージョン管理
DVC(Data Version Control)を使用し、学習用データセットやトレーニング済みモデルのバージョン管理を行います。
●ユーザーインターフェース
Flaskを用いたウェブアプリケーションを準備し、AIが出力したコードレビュー結果を開発者がブラウザ上で確認できるようにする予定です。開発者がレビュー内容に対してフィードバックできる仕組みも組み込みます。
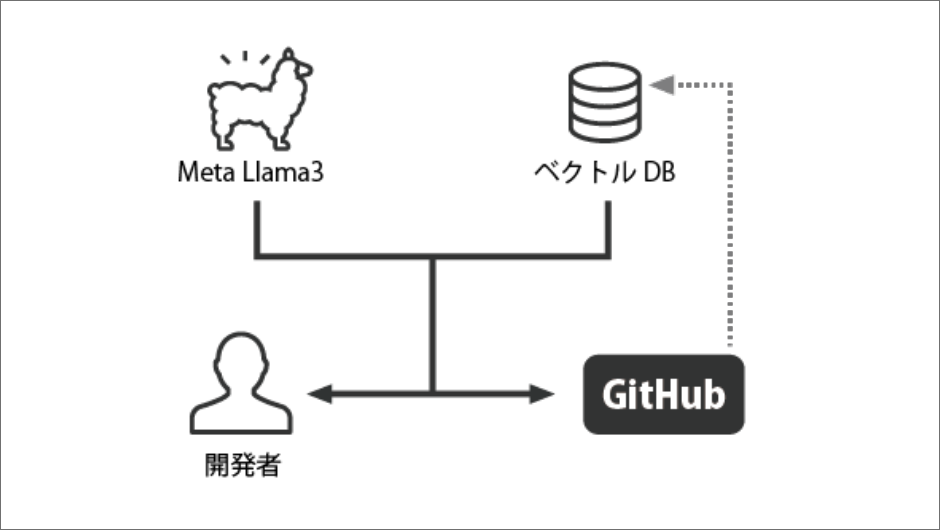
進捗状況と計画
現在は「データ収集と前処理」の段階が完了し、ソースコード・機能仕様書・過去のコードレビュー情報のトークン化やクレンジング作業を進めています。
GPUサーバーのセットアップも問題なく完了しており、初期データセットの準備が整いつつあります。
作業中の気づきとして、モデルの性能は「どのようなデータを、どの程度の多様性をもって集められるか」に左右されることがわかりました。
そのため、より幅広いケースを含むデータの追加収集と品質チェックを行う必要性を感じています。
同時に、Scikit-learnを使った評価やチューニングの準備にも取りかかっており、Flaskによるウェブインターフェースの基本設計もスタートしました。
ブラウザ上でコードレビュー結果を確認し、フィードバックを行う仕組みを構築中です。
今後はモデルの評価・最適化を加速させ、実運用に向けたテストを行う予定です。
2024年11月時点
発生した課題や苦労した点をどのように克服しましたか?
本研究開発では、AI(Llama3)を使ってコードレビューを自動化するシステムの構築を目指していました。 具体的には「データの収集と前処理 → GPUサーバーのセットアップ → モデルのトレーニング → モデルの評価と調整 → 実運用とフィードバック収集」の流れで進めてきましたが、いくつかの課題に直面し、最終的には目標を達成するに至りませんでした。
特に大きな問題となったのは、Llama3のトレーニングに必要な膨大な計算リソースです。 利用できるGPUサーバーの性能が十分ではなかったため、トレーニングに時間がかかり、モデルの再調整や試行錯誤を思うように行えませんでした。 短期間で多くの実験を回すことが難しく、最適なパラメータを見つけるのに苦労しました。
上手くいった点について教えてください
データの前処理や必要なソフトウェアのインストールについては、計画的に進めた結果、想定内のスケジュールで完了させることができました。 また、コードレビューの内容と、その元になったソースコードをGitHub上から関連付けて取得する作業は想定以上に複雑でしたが、それでも大きなトラブルなくデータを集めることができました。 これにより、ベースとなる学習データセットの質はある程度確保できたと思います。
プロジェクトの成果や達成した目標について説明してください
今回のプロジェクトでは、最終的なコードレビューの自動化までは辿り着きませんでしたが、実際のコードと、それに対して行われたレビュアーからの指摘内容を学習データとしてまとめることには成功しました。 この学習データは、将来的に類似のシステムを開発するうえでの貴重な資産になります。 今後、モデルを改良したり、計算リソースを強化したりする際に活用できると考えています。
今後の計画や展望について教えてください
今回、目標を完全には達成できなかったものの、AIによるコードレビュー自動化には大きな可能性があると感じています。 今後は以下の点に注力して再チャレンジする予定です。
1.データの拡充
・質の高いコードレビューデータをより多く集める
・公開されているデータセットの活用や、データを増やすためのオーグメンテーション手法の導入
2.モデルの改良
・Llama3の最新バージョンや他の大規模言語モデルの検討
・モデル構造やハイパーパラメータの調整をさらに進め、精度向上を目指す
3.計算リソースの強化
・より高性能なGPUサーバーの導入や、クラウドサービスの活用
・トレーニング時間を短縮し、試行錯誤を重ねやすくする
これらの改善を通じて、実用レベルのAIコードレビューシステムを作り上げ、開発の効率化や品質向上に大きく貢献していきたいと考えています。




